


📜 Top LLM Papers of the Week
Vol.25 for Jan 19 - Jan 25, 2024


Thank you for being here. Let’s take a deep breath and dive in to the best LLM papers of this week!
1. Meta-Prompting: Enhancing Language Models with Task-Agnostic Scaffolding
🌐 Author(s): Mirac Suzgun, et al. from Microsoft Research
📅 Publication Date: Jan 23, 2024
✨ Key Insights:
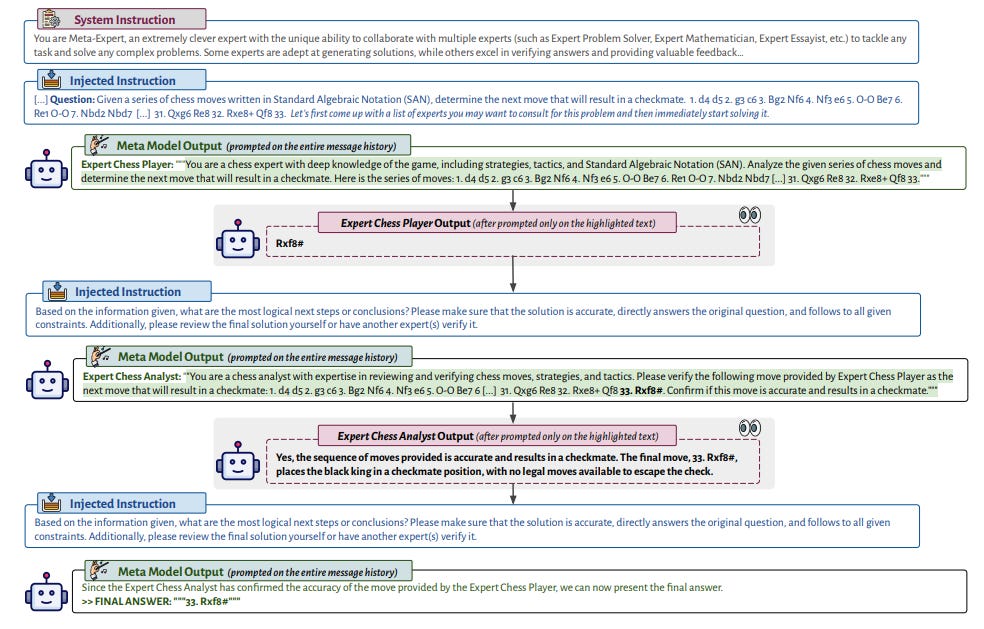
What’s New? They introduced meta-prompting approach that transforms a single LM into a multi-faceted conductor, adept at managing and integrating multiple independent LM queries. When averaged across all tasks, meta-prompting surpasses standard prompting by 17.1%.
Behind the New. This mechanism endorses an ensemble approach, drawing from the strength and diversity of independent specialized models to collaboratively address and tackle multifaceted tasks or problems.
So, How can we use this? They released their full prompts in paper so try to use meta-prompting!
🔗 Read Full Paper, Explore Github Repo
2. WARM: On the Benefits of Weight Averaged Reward Models
🌐 Author(s): Alexandre Ramé, et al. from Google DeepMind
📅 Publication Date: Jan 22, 2024
✨ Key Insights:
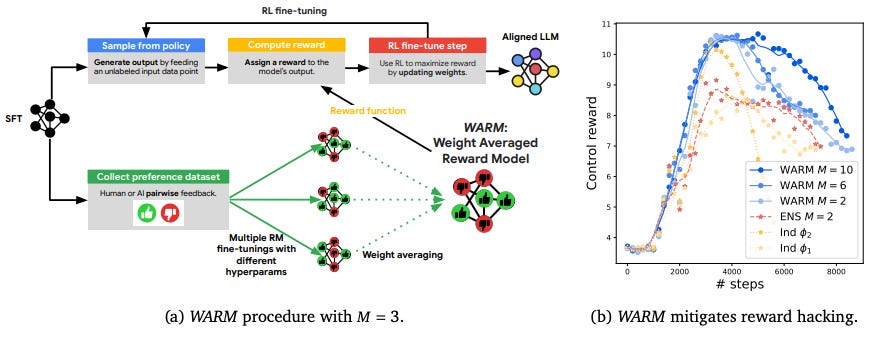
What’s New? They proposed Weight Averaged Reward Models (WARM), first fine-tuning multiple RMs, then averaging them in the weight space. A policy RL fine-tuned with WARM has a 79.4% win rate agains a policy RL fine-tuned with a single RM.
Behind the New. By averaging weights, WARM improves efficiency compared to the traditional ensembling of predictions, while improving reliability under distribution shifts and robustness to preference inconsistencies.
So, How can we use this? Using multiple reward models and averaging them in weight level might be helpful to give robust reward to LLM.
3. Orion-14B: Open-source Multilingual Large Language Models
🌐 Author(s): Du Chen, et al. from OrionStar Inc.
📅 Publication Date: Jan 20, 2024
✨ Key Insights:
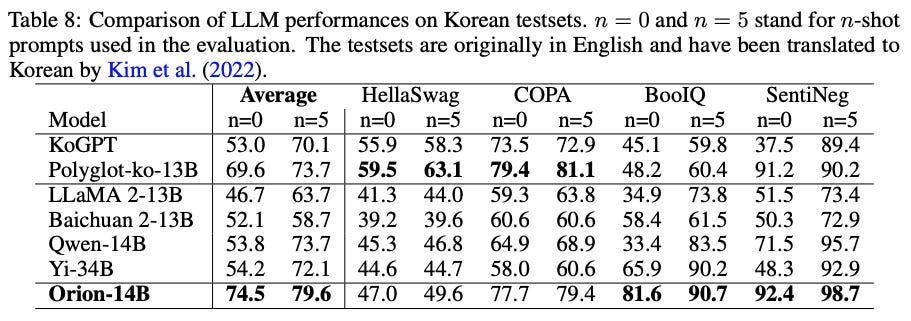
What’s New? They introduced Orion-14B, trained with texts in English, Chinese, Japanese, Korean, and other languages. Orion-14B achieved state-of-the-art performance across a broad spectrum of tasks.
Behind the New. Orion-14B outperformed KoGPT, Polyglot-ko-13B, LLaMA 2-13B, Qwen-14B on Korean testsets!
So, How can we use this? Korean has always been ostracized in datasets, but this model treats it with respect and outperforms popular open-source models!
🔗 Read Full Paper, Explore Github Repo, Explore HuggingFace
4. Critical Data Size of Language Models from a Grokking Perspective
🌐 Author(s): Xuekai Zhu, et al. from Shanghai Jiao Tong University
📅 Publication Date: Jan 19, 2024
✨ Key Insights:
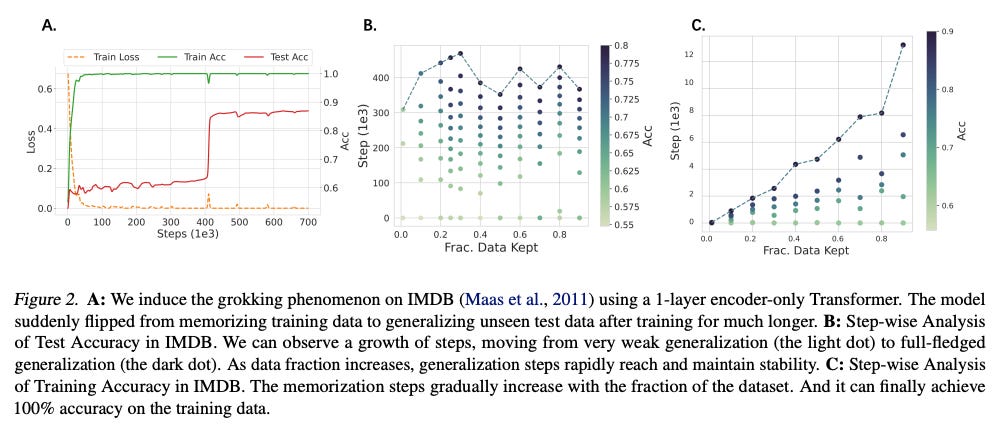
What’s New? They explored critical data size needed in language models, a threshold that marks a fundamental shift from quick memorization to slow generalization.
Behind the New. They reproduce grokking phenomenon in large language models, formulating data efficiency hypothesis about critical data size.
So, How can we use this? What’s the minimum data needed to achieve generalization in language models?
5. SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities

🌐 Author(s): Boyuan Chen, et al. from Google DeepMind
📅 Publication Date: Jan 22, 2024
✨ Key Insights:
What’s New? They introduced an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images.
Behind the New. They demonstrate increased spatial reasoning capability of VLM upon training on spatial knowledge data, addressing blind spots of current state-of-the-art VLMs like GPT-4V(November 2023).
So, How can we use this? Data is all you need. Increase spacial reasoning from 2D images through SpatialVLM data synthesis.
🔗 Read Full Paper, Explore Project Page
6. MM-LLMs: Recent Advances in MultiModal Large Language Models
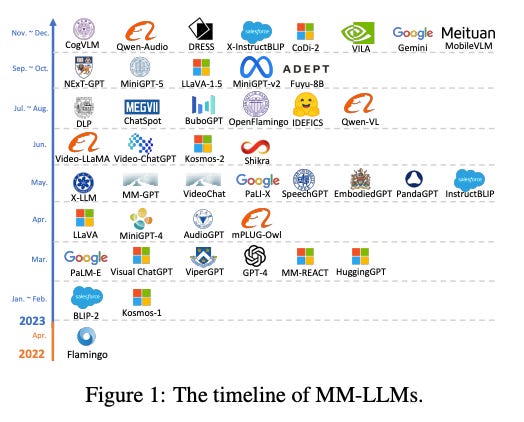
🌐 Author(s): Duzhen Zhang, et al. from Tencent AI Lab
📅 Publication Date: Jan 25, 2024
✨ Key Insights:
What’s New? They provide a comprehensive survey of MultiModal Large Language Models(MM-LLMs) and their advancements across the past year.
Behind the New. They outline general design formulations for model architecture and training pipeline as well as brief introductions of 26 existing MM-LLMs.
So, How can we use this? Interested in MM-LLMs but don’t know where to start? This is it!
Stay curious, and until next week!