


📜 Top LLM Papers of the Week
Vol.8 for Sep 22 - Sep 28, 2023

Thank you for being here! This is the eighth article of newsletter. Let’s take a deep breath and dive in to the best LLM papers of this week!
1. Qwen Technical Report

🌐 Author(s): Jinze Bai, et al. from Alibaba
📅 Publication Date: Sep 28, 2023
✨ Key Insights:
What’s New? They introduced QWEN, the first Alibaba’s LLM series. It includes QWEN, the base pretrained language models, QWEN-CHAT, finetuned with RLHF, and CODE-QWEN which is coding-specialized models. This model outperformed the previous open-source models like LLaMA-2.
Behind the New. They adopted the approach of LLaMA in building the model architecture and training. QWEN 14B performed better than LLaMA-2 34B. They also used PPO for RLHF, same as other open-source LLMs.
So, How can we use this? QWEN is open-sourced model so you can try this model in their website, or hugging-face. Also, there are a lot of techniques in this paper, including data, pre-training, alignment, etc. Please try to read this paper!
🔗 Read Full Paper, Explore Github Repo
2. Effective Long-Context Scaling of Foundation Models
🌐 Author(s): Wenhan Xiong, et al. from Meta
📅 Publication Date: Sep 27, 2023
✨ Key Insights:
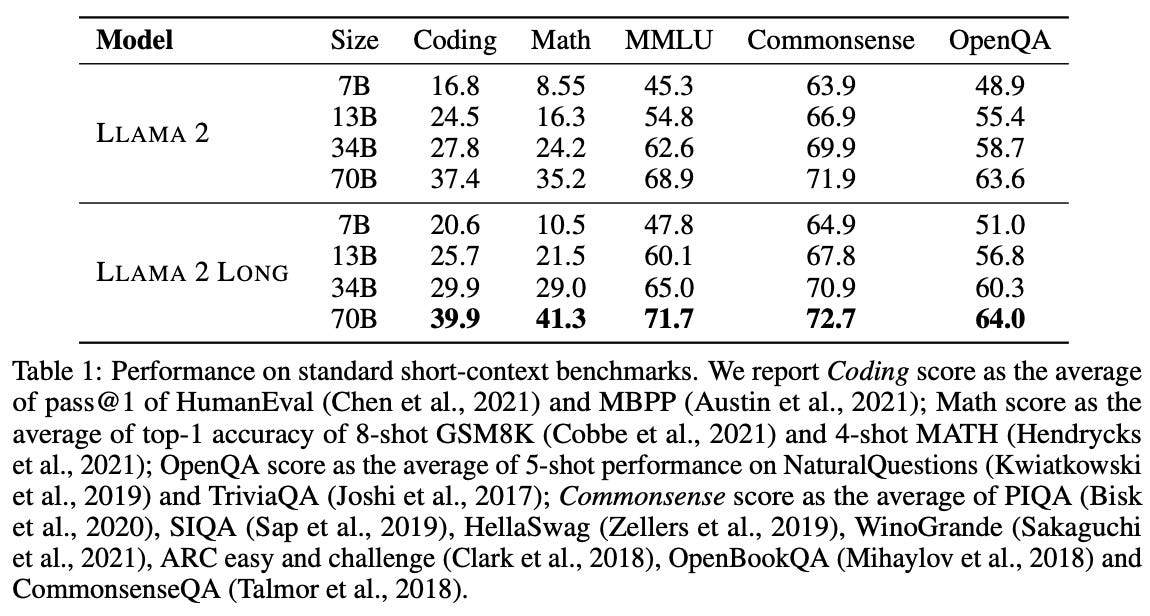
What’s New? They presented a series of long-context LLMs that support effective context windows of up to 32.768 tokens. They introduced LLaMA 2 LONG, pre-trained from LLaMA-2 with longer training sequences and on a dataset where long texts are upsampled.
Behind the New. They suggested that having abundant long texts in the pre-train dataset is not the key to achieving strong performance. Also, they verified that long context continual pre-training is more efficient and similarly effective compared to pre-training from scratch with long sequences.
So, How can we use this? Be interested in continual pre-training. Also, keep in mind that the amount of data is not important. Interestingly, even with most of the long texts removed, the LLaMA-2 LONG can still obtain most of the performance gain over LLaMA-2.
3. Defending Against Alignment-Breaking Attacks via Robustly Aligned LLM

🌐 Author(s): Bochuan Cao, et al. from The Pennsylvania State University
📅 Publication Date: Sep 18, 2023
✨ Key Insights:
What’s New? They introduced a Robustly Aligned LLM (RA-LLM) to defend against potential alignment-breaking attacks. It checks LLM with a robust alignment checking function, without requiring any expensive retraining or fine-tuning. RA-LLM can successfully defend agains adversarial prompts and jailbreaking prompts by reducing their attack success rates from nearly 100% to around 10% or less.
Behind the New. LLMs can be misused to generate harmful or malicious content. Their motivation builds upon the fact that the target LLM has already been aligned and is able to reject commonly seen malicious requests. They randomly drop a certain portion of the request and check whether the response still pass the alignment well.
So, How can we use this? Protect your LLM service from malicious attack by building RA-LLM without high costs. Be interested in LLM security. 👉 Go to Awesome-LLM-Security Repo
4. QA-LoRA: Quantization-Aware Low-Rank Adaptation of Large Language Models

🌐 Author(s): Yuhui Xu, et al. from Huawei
📅 Publication Date: Sep 26, 2023
✨ Key Insights:
What’s New? They proposed a quantization-aware low-rank adaptation (QA-LoRA) algorithm. QA-LoRA has exactly same complexity as QLoRA with PTQ and is much more efficient than QLoRA without PTQ.
Behind the New. The motivation lies in the imbalanced degrees of freedom of quantization and adaptation, and the solution is to use group-wise operators which increase the degree of freedom of quantization meanwhile decreasing that of adaption.
So, How can we use this? QA-LoRA is easily implemented with a few lines of code. Try to apply QA-LoRA in your LLM for quantization.
🔗 Read Full Paper, Explore Github Repo
5. ReConcile: Round-Table Conference Improves Reasoning via Consensus among Diverse LLMs
🌐 Author(s): Justin Chih-Yao Chen, et al. from University of North Carolina at Chapel Hill
📅 Publication Date: Sep 22, 2023
✨ Key Insights:
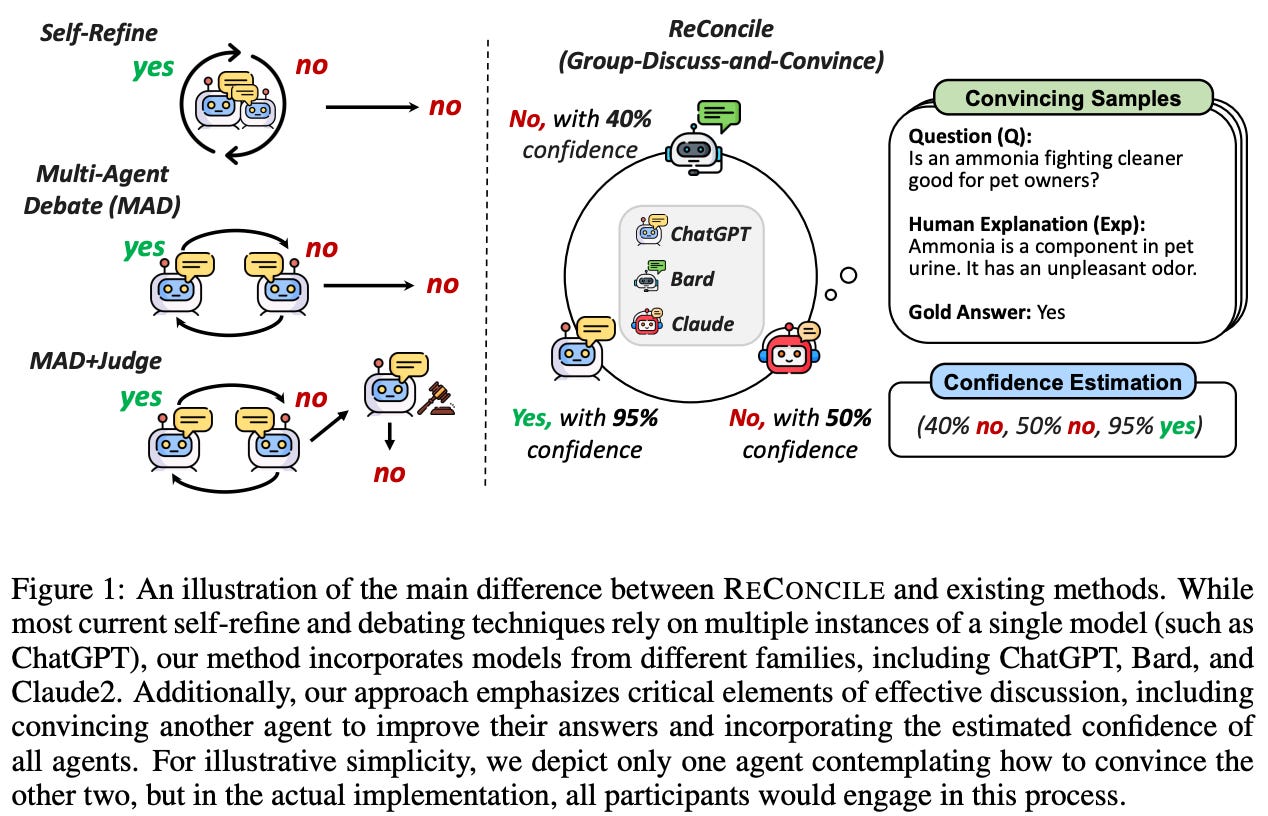
What’s New? They proposed RECONCILE, a multi-model multi-agent framework designed as a round table conference among diverse LLM agents to foster diverse thoughts and discussion for improved consensus. They demonstrated that RECONCILE significantly enhances the reasoning performance of the agents, surpassing prior single-agent and multi-agent.
Behind the New. In RECONCILE, each agent first generates an answer, then all agents enter a multi-round discussion phase. This system leveraged them in an in-context learning framework to teach models to generate their own convincing explanations. They estimate an agent’s uncertainty and compute a weighted vote as the final answer.
So, How can we use this? Are you solving reasoning task with LLMs? Please try to use multi-agent system and start easily with this framework! Many papers verified that multi-agent can be better than single-agent in complex reasoning tasks.
🔗 Read Full Paper, Explore Github Repo
6. Self-Explanation Prompting Improves Dialogue Understanding in Large Language Models
🌐 Author(s): Haoyu Gao, et al. from Alibaba
📅 Publication Date: Sep 22, 2023
✨ Key Insights:
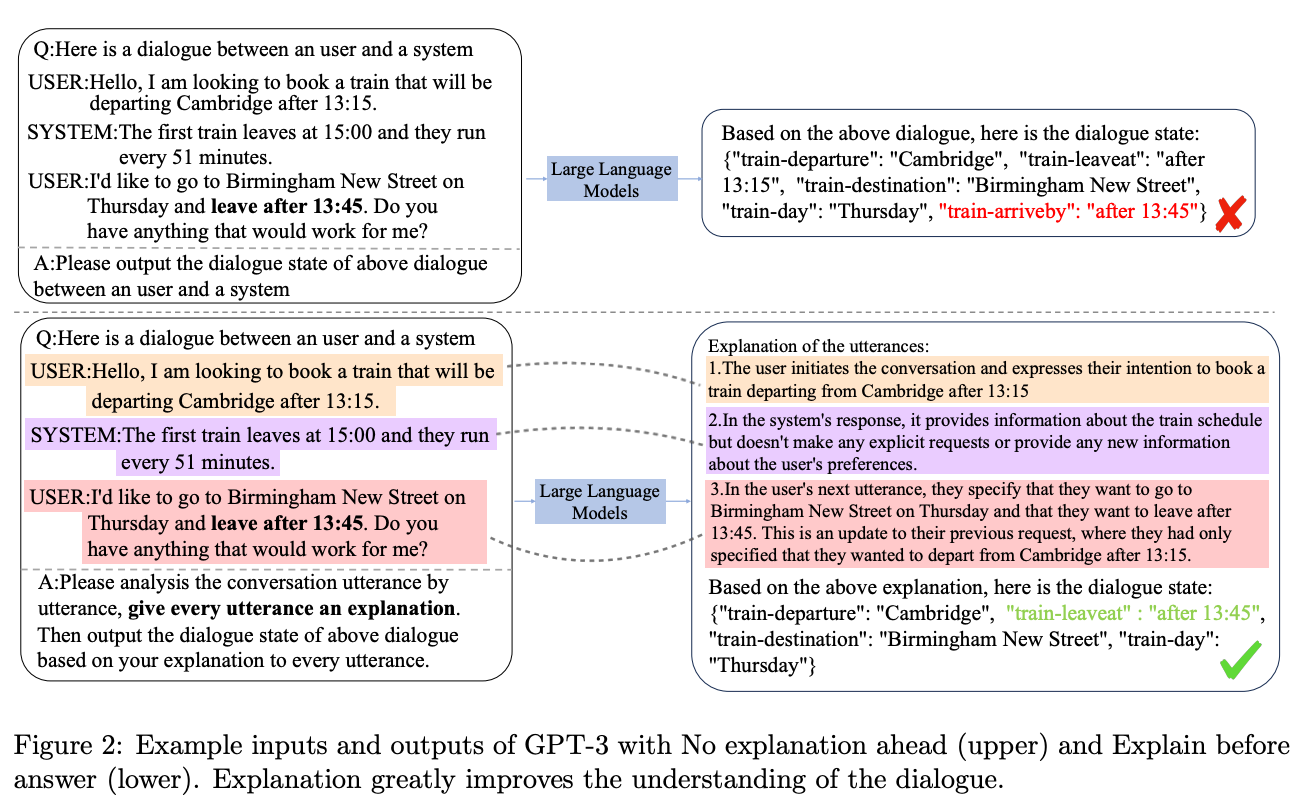
What’s New? They proposed “Self-Explanation” prompting strategy to enhance the comprehension abilities of LLMs in multi-turn dialogues. Their method consistently outperformed other zero-shot prompts and matched or exceeded the efficacy of few-shot prompts.
Behind the New. The concept of self-explanation, originating from psychological research, involves learners generating explanations for themselves while processing unfamiliar content.
So, How can we use this? Just add “first summarize the dialogue, then ..” in your prompt! Self-explanation method can make your LLM better at dialog understanding.
7. LORD: Low Rank Decomposition Of Monolingual Code LLMs For One-Shot Compression
🌐 Author(s): Ayush Kaushal, et al. from Nolano AI
📅 Publication Date: Sep 25, 2023
✨ Key Insights:
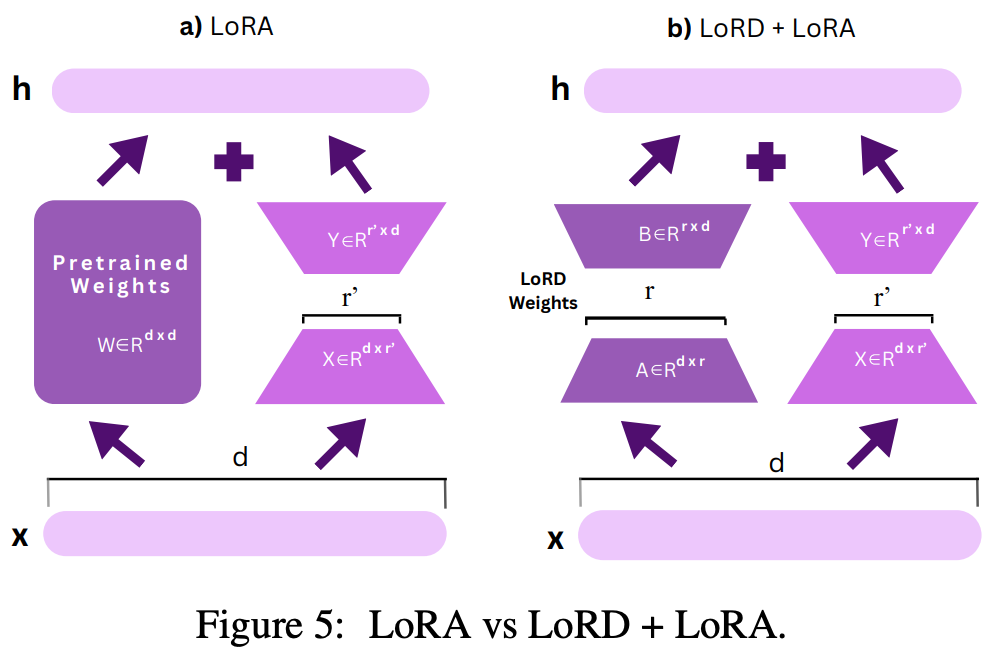
What’s New? They compressed LLMs for monolingual Code generation via Low Rank Decomposition (LoRD). They used LoRD to compress StarCoder 16B to 13.2B parameter with no drop! The compressed models speeds up inference by up to 22.35% with just a single line of change.
Behind the New. Low Rank Decomposition of matrix is splitting a large matrix into a product of two smaller matrix. This offers a means for compression that reduces the parameters of a model without sparsification, and hence delivering more speedup.
So, How can we use this? LoRD is really easy to adopt your code. Just replace
nn.Linear(in, out)withnn.Sequential(nn.Linear(in, rank), nn.Linear(rank, out))!
8. Attention Satisfies: A Constraint-Satisfaction Lens on Factual Errors of Language Models

🌐 Author(s): Mert Yuksekgonul, et al. from Microsoft Research
📅 Publication Date: Sep 26, 2023
✨ Key Insights:
What’s New? They discovered a strong positive relation between the model’s attention to constraint tokens and the factual accuracy of its responses. They predict constraint satisfaction and factual errors, and allows early error identification!
Behind the New. Recent work investigates the internal activations of LMs to understand the mechanics of factual recall. Some papers suggested that attention layers transfer factual knowledge to where it will be used.
So, How can we use this? Quite interesting! We can predict the factual errors and it means, we can reduce hallucination from LLMs.
Other awesome papers what I read in this week
DeepSpeed-VisualChat: Multi-Round Multi-Image Interleave Chat via Multi-Modal Causal Attention
Only 5% Attention Is All You Need: Efficient Long-range Document-level Neural Machine Translation
Enhancing Zero-Shot Chain-of-Thought Reasoning in Large Language Models through Logic
Aligning Large Multimodal Models with Factually Augmented RLHF
ConPET: Continual Parameter-Efficient Tuning for Large Language Models
An In-depth Survey of Large Language Model-based Artificial Intelligence Agents
RAGAS: Automated Evaluation of Retrieval Augmented Generation
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
A Survey of Chain of Thought Reasoning: Advances, Frontiers and Future
NLPBench: Evaluating Large Language Models on Solving NLP Problems
The ARRT of Language-Models-as-a-Service: Overview of a New Paradigm and its Challenges
AnyMAL: An Efficient and Scalable Any-Modality Augmented Language Model
Sorry for the delay. Yesterday was Chuseok, a traditional Korean holiday. As an apology, I added a list of all the papers that caught my attention this week! I hope you find them useful! Stay curious, and until next week!