

📜 Top LLM Papers of the Week
📜 Top LLM Papers of the Week
Vol.12 for Oct 20 - Oct 26, 2023


Thank you for being here! This is the twelfth article of this newsletter. Let’s take a deep breath and dive in to the best LLM papers of this week!
1. Zephyr: Direct Distillation of LM Alignment
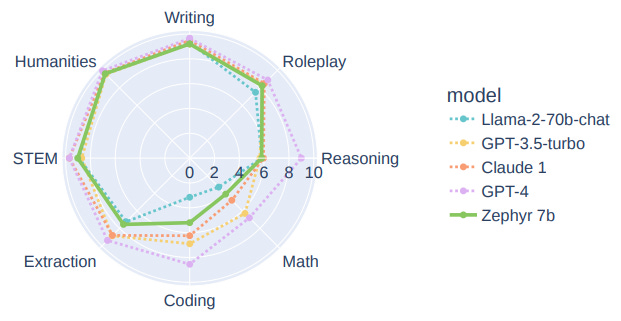
🌐 Author(s): Lewis Tunstall, et al. from The H4 Team (HuggingFace)
📅 Publication Date: Oct 25, 2023
✨ Key Insights:
What’s New? They introduce Zephyr, trained with distilled direct preference optimization (dDPO) and the use of preference data from AI Feedback (AIF). Zerphyr-7B surpasses Llama-2-Chat-70B on MT-Bench.
Behind the New. Previous research has shown that applying distilled supervised fine-tuning (dSFT) on larger models significantly improves task accuracy (e.g. WizardLM). Zephyr uses Mistral 7B as the starting point due to its strong performance.
So, How can we use this? You can use Zephyr freely in HuggingFace!
🔗 Read Full Paper, Explore Github Repo
2. Woodpecker: Hallucination Correction for Multimodal Large Language Models

🌐 Author(s): Shukang Yin, et al. from Tencent YouTu Lab
📅 Publication Date: Oct 24, 2023
✨ Key Insights:
What’s New? They introduce a hallucination correction method in Multimodal Large Language Models (MLLMs), making sure that the generated text is consistent to the image content.
Behind the New. They introduce a training-free method named Woodpecker, correcting hallucinations from text through five stages: key concept extraction, question formulation, visual knowledge validation, visual claim generation, and hallucination correction.
So, How can we use this? If you are suffering from hallucination in multimodal setting, try using this correction methodology in conjunction to your MLLM.
3. Visual Cropping Improves Zero-Shot Question Answering of Multimodal Large Language Models
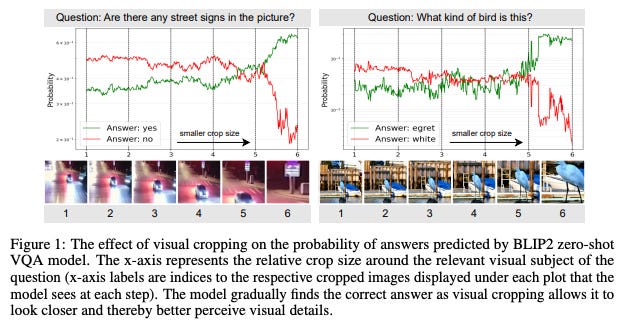
🌐 Author(s): Jiarui Zhang, et al. from University of Southern California
📅 Publication Date: Oct 24, 2023
✨ Key Insights:
What’s New? They propose automatic visual cropping methods to improve the zero-shot performance of multimodal LLMs. They show that their zero-shot accuracy is very sensitive to the size of the visual object of the question, declining up to 46% with size.
Behind the New. They use CLIP, YOLOv8 pretrained on COCO, SAM (segment anything model) for cropping images. While YOLO is the fastest method, they recommend using CLIP in practice since it provides the best overall balance between accuracy and inference time.
So, How can we use this? When you are doing VQA, please make the visual object of the question bigger in the picture! This can be used in visual prompt techniques.
🔗 Read Full Paper, Explore GitHub Repo
4. DDCoT: Duty-Distinct Chain-of-Thought Prompting for Multimodal Reasoning in Language Models
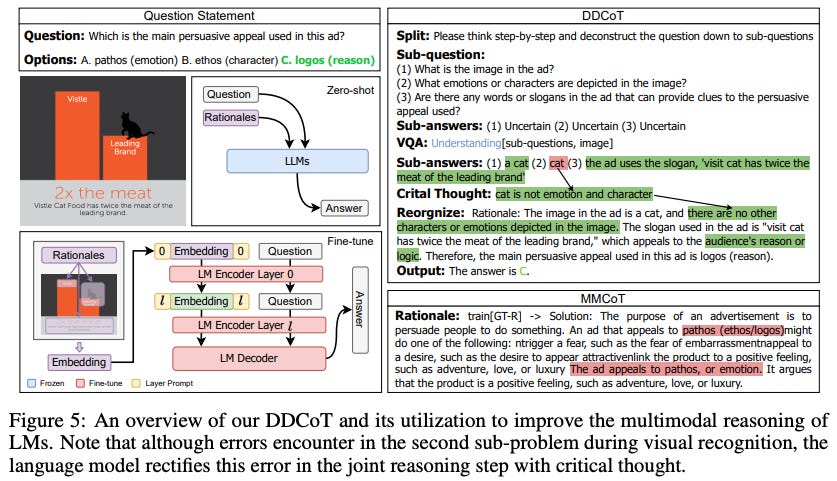
🌐 Author(s): Ge Zheng, et al. from ShanghaiTech University
📅 Publication Date: Oct 26, 2023
✨ Key Insights:
What’s New? They present a multimodal CoT prompting approach called Duty-Distinct Chain-of-Thought Prompting(DDCoT), which generate multimodal rationales using language-only LLMs.
Behind the New. The proposed DDCoT is composed of two factors: (1) critical thinking - keeping a healthy dose of skepticism to improve correctness and (2) let everyone do their jobs - divide labor and work together, prompting the LLMs to identify their roles.
So, How can we use this? CoT seems to be a strong topic crossing over from LLM to Multimodal environment to strengthen LLM reasoning. In the case for generalizable and explainable rationale for MLLMs, try using DDCoT prompting.
5. SkyMath: Technical Report
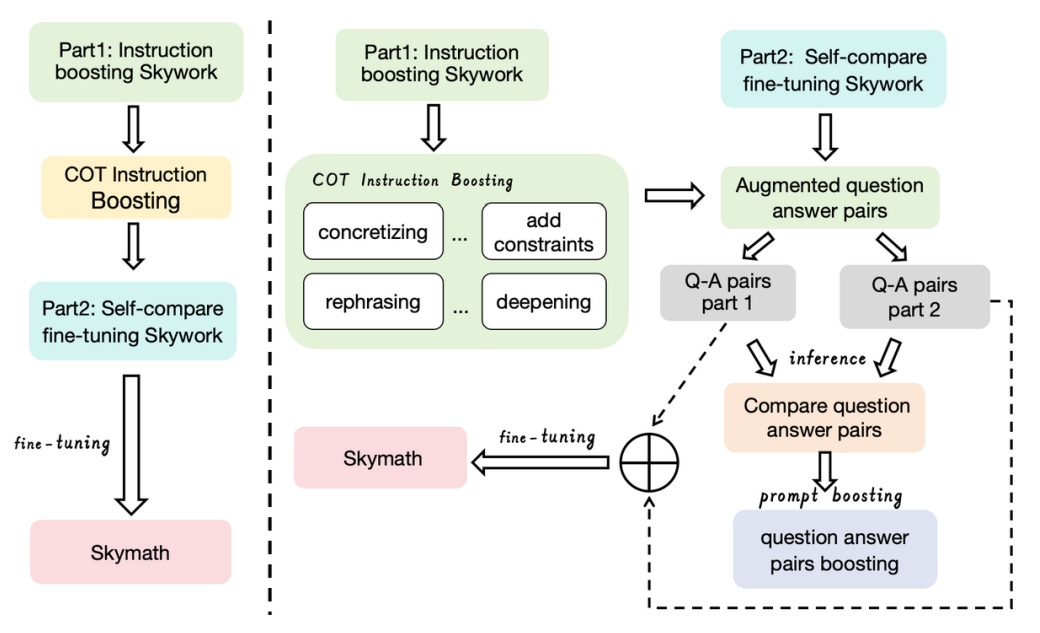
🌐 Author(s): Liu Yang, et al. from Kunlun Inc.
📅 Publication Date: Oct 26, 2023
✨ Key Insights:
What’s New? They present SkyMath, a large language model for mathematics with 13 billion parameters. It is stated that SkyMath outperforms all known open-source models of similar size and has established a new SOTA performance on GSM8K.
Behind the New. The architecture of SkyMath is composed of two steps: (1) instruction boosting - which constructs high complexity math instructions and (2) self-compare fine tuning - which uses previously generated answers as hints to guiding LLM.
So, How can we use this? Unfortunately, the authors have not revealed the code for their model but their method is free to explore in the paper.
6. Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries

🌐 Author(s): Yiqiao Jin, et al. from Georgia Institute of Technology
📅 Publication Date: Oct 23, 2023
✨ Key Insights:
What’s New? They conduct automated and human evaluation experiments with English, Chinese, Hindi, and Spanish. They show that the answers in non-English languages are less correct, less consistent, less verifiable.
Behind the New. They propose XLingEval, a comprehensive evaluation framework for LLMs in the healthcare domain that focuses on three fundamental criteria: correctness, verifiability, and consistency. They propose XLingHealth, a Cross-Lingual Healthcare benchmark for clinical health inquiry.
So, How can we use this? We have no choice. Please use English when you are using LLMs.
🔗 Read Full Paper, Explore Github Repo
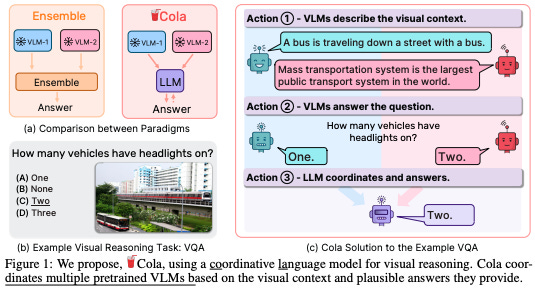
7. Large Language Models are Visual Reasoning Coordinators
🌐 Author(s): Liangyu Chen, et al. from Nanyang Technological University
📅 Publication Date: Oct 23, 2023
✨ Key Insights:
What’s New? They propose Cola, coordinates multiple VLMs for visual reasoning. Their key insight is that a LLM can efficiently coordinate multiple VLMs by facilitating natural language communication that leverages their distinct and complementary capabilities.
Behind the New. They also propose Cola-FT, an instruction tuning variant, achieves SOTA performance on visual question answering (VQA). Their in-context learning variant, Cola-Zero, exhibits competitive performance in zero and few-shot settings.
So, How can we use this? Let VLMs communicate each other by LLM!
🔗 Read Full Paper, Explore Github Repo
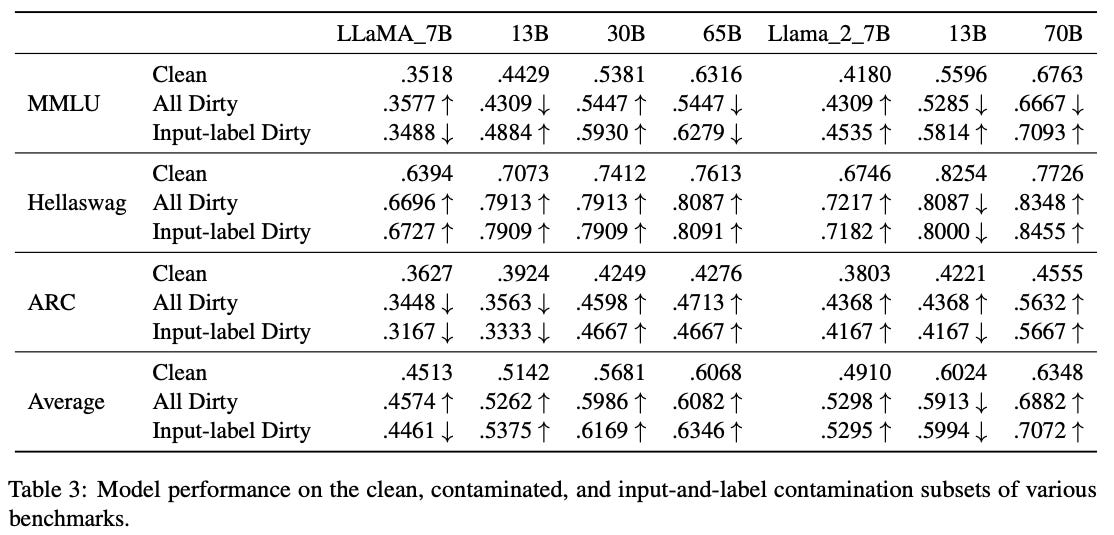
8. An Open Source Data Contamination Report for Llama Series Models
🌐 Author(s): Yucheng Li, et al. from University of Surrey
📅 Publication Date: Oct 26, 2023
✨ Key Insights:
What’s New? The author throws the question of data contamination in large language models and their evaluation, reporting contamination level for the LlaMA series models.
Behind the New. The paper analyzes LLaMA models’ contamination on popular QA benchmarks. They first check whether the test examples of LLaMA can be found on the internet, measuring the contamination level. Then they calculate the model performance on the clean/contaminated subsets to evaluate the impact of data contamination.
So, How can we use this? As LLM models are being trained on large corpus of data spread across the internet, data contamination is a factor to keep in mind of when evaluating. Are you sure your testing data has not been leaked to your LLM?
🔗 Read Full Paper, Explore Github Repo
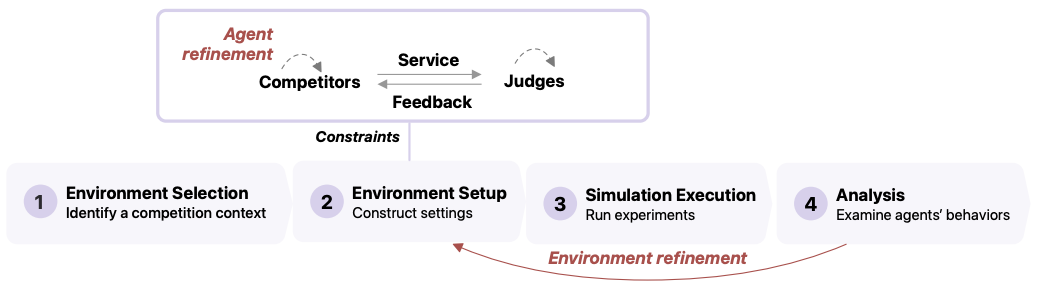
9. CompeteAI: Understanding the Competition Behaviors in Large Language Model-based Agents
🌐 Author(s): Qinlin Zhao, et al. from Microsoft Research
📅 Publication Date: Oct 26, 2023
✨ Key Insights:
What’s New? While most work on LLM agents focus on collaboration, this work explores competition, another important mechanism that fosters the development of society and economy.
Behind the New. They propose a general framework studying competition between agents. They also share their environment for agents that fosters competitive behaviors utilizing GPT-4. It is said that the agent’s actions aligned with already established sociological and economic theories.
So, How can we use this? If you have only focused on cooperation and collaboration behaviors of agents, how about making them compete with each other instead?
Stay curious, and until next week!